Synergizing Vector Databases with LangChain
The Path to Enhance Contextual Reasoning
LangChain, as an open-source framework initially released in October 2022 by Harrison Chase, provides a solution to enhance environment awareness with LLMs, backboned by vector databases. This project quickly went viral, with significant features to connect other sources of data, such as the internet or personal files. The main use case for LangChain is to build chat-based applications enabled by LLMs. Vector databases, which are a collection of data where each entry is represented as a vector, typically used for efficient similarity searches and machine learning tasks, enrich LangChain’s reasoning abilities. In an interview in June 2023, Harrison highlighted that the most valuable application nowadays is "chat over your documents." LangChain pushes LLMs to the boundaries of semantic search, which enhances the interaction and responsiveness of the chat experience, allowing for smoother and more dynamic conversations.
Although LangChain began as an open-source project, it has become a meteoric rise for startups to help navigate some of the issues with LLMs. For example, vector databases and contextual-specific generative AI applications are emerging. In 2023, LangChain and vector databases have gained significant financial investments, reflecting the growing interest and confidence in their potential to advance Language Models (LLMs) in terms of comprehension and reasoning.
LangChain has raised between $20 million and $25 million in funding at a valuation of at least $200 million from Sequoia. The deal was headed up by growth investor Sonya Huang, who has been a prominent evangelist for the generative AI movement.
In April 2023, Pinecone vector database raised $100 million in Series B, with valuation of $750 million. The company has now raised $138 million, with Investors including Menlo Ventures and Wing Venture Capital. Pinecone's first-to-market advantage has positioned it as a market leader in the vector database space, secured over 1,500 customers in 2022 by offering a flexible and efficient solution for semantic search and knowledge management.
In April 2023, Weaviate announced a $50 million funding led by Index Ventures and Battery Ventures. The funding will be spent in team expansion and development acceleration to satisfy the growing AI application development market.
Chroma Inc., a database provider specializing in AI applications, has secured $18 million in seed funding. The investment was led by Quiet Capital, with contributions from executives at Hugging Face Inc. and several other tech companies. Chroma's open-source database, which is tailored for artificial intelligence applications, has gained significant traction, with over 35,000 downloads since its launch less than two months ago.
LangChain and Vector Databases Concept and Technology Review
Advantages of LangChain on Large Language Models
LangChain enhances large language models by introducing memory management, world modeling, and seamless integration capabilities. It enables models to store and access information from past interactions, maintain context, and provide coherent responses. LangChain incorporates a world modeling component that represents entities and their relationships, aiding the model's understanding and reasoning in long contexts. It seamlessly integrates with LLMs, enhancing their conversational context understanding and response generation. These enhancements enable LLMs to handle complex conversational scenarios and deliver more intelligent and engaging conversational AI experiences. LangChain enhances the contextual awareness and decision-making abilities of LLMs in four aspects:
- Common Sense Improvement
LLMs lack inherent knowledge of the world and rely solely on the patterns and information present in the training data. As a result, they may generate responses that seem plausible but lack common sense or accurate understanding of specific domains. LangChain enhances the responses by linking to specific domain knowledge.
- Factual Accuracy Enhancement
LLMs are not explicitly trained to verify the accuracy of the information they generate. While they can provide coherent and contextually appropriate responses, they may also generate inaccurate or false information, especially when dealing with complex or specialized topics. LangChain can improve the accuracy by linking with tailored-made domain knowledge.
- Long Contexts Awareness
LLMs have a maximum token limit for input sequences, which restricts their ability to handle long contexts or documents. When presented with lengthy inputs, LLMs may struggle to generate coherent and meaningful responses. With the use of vector databases for contextual linkage, LangChain enhances contextual awareness and reasoning abilities.
- Explicit Reasoning Enhancement
LLMs lack explicit Lack reasoning abilities and may not provide clear justifications or explanations for their answers. They generate responses based on patterns in the training data without explicitly understanding the underlying logic or reasoning. Backboned by vector databases, LangChain can help link up domain-specific knowledge to LLMs, which enhances reasoning abilities in specific fields such as healthcare, finance and engineering.
Key Modules in LangChain
There are six modules in LangChain which are Model I/O, Prompts, Retrieval, Chains, Memory, Agents and Callbacks.
- Prompts
Prompts are specific input queries or statements given to models to elicit desired responses. They guide the language models in generating contextually relevant answers, tailored to gather information, answer questions, or perform specific tasks. Chains are sequences of prompts and responses that create meaningful conversations. They enable the flow of communication between users and LangChain, ensuring dynamic and contextually rich interactions. Embeddings represent words as multidimensional vectors, capturing their semantic meaning and relationships.
- Model I/O
It is important to recognize that there are two types of language models in LangChain: LLMs and chat models. LLMs operate by taking a string as input and returning a string as output. On the other hand, chat models function by taking a list of messages as input and returning a chat message as output. Chat messages consist of two components: the content itself and a role that indicates the source of the content, such as a human, an AI, the system, a function call, or a generic input. These models play a pivotal role in understanding the nuances of language, including context, syntax, and semantics, enabling accurate comprehension of user input. Figure 1 illustrates the input and output of LLM and Chat Model.
Figure 1. Model I/O
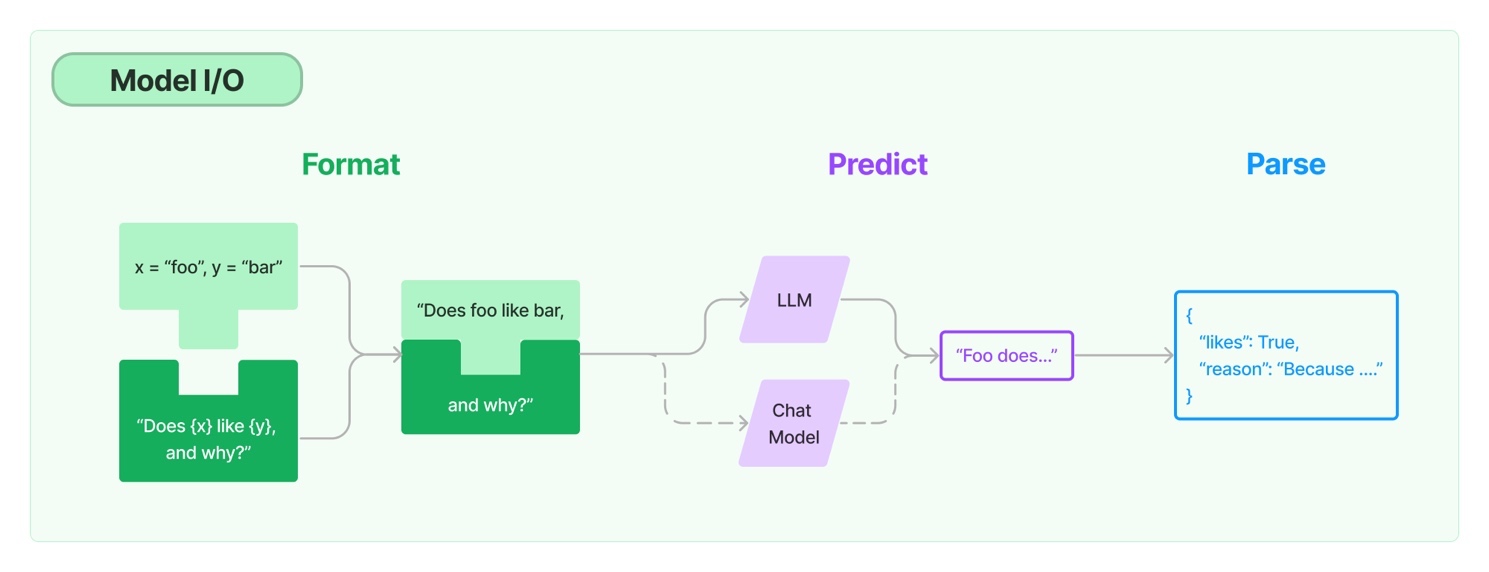 Source: LangChain
Source: LangChain
- Memory
Memory management is important for contextual awareness. Vector stores are databases that store mathematical representations (vectors) of words and phrases. As shown in figure, these vector representations capture the semantic meaning and relationships between words. Vector stores are particularly useful for tasks like question answering and summarization, as they enable finding similar words and phrases. Vector databases maintain a constantly updated world model, which allows it to perform actions like maintaining information about entities and their relationships. A memory system needs to support two basic actions: reading and writing. A chain, which defines the core execution logic and receives inputs from both the user and memory, interacts with the memory system twice during a run. Figure 2 shows the mechanism of memory retrieval.
Figure 2. Memory Retrieval by LangChain
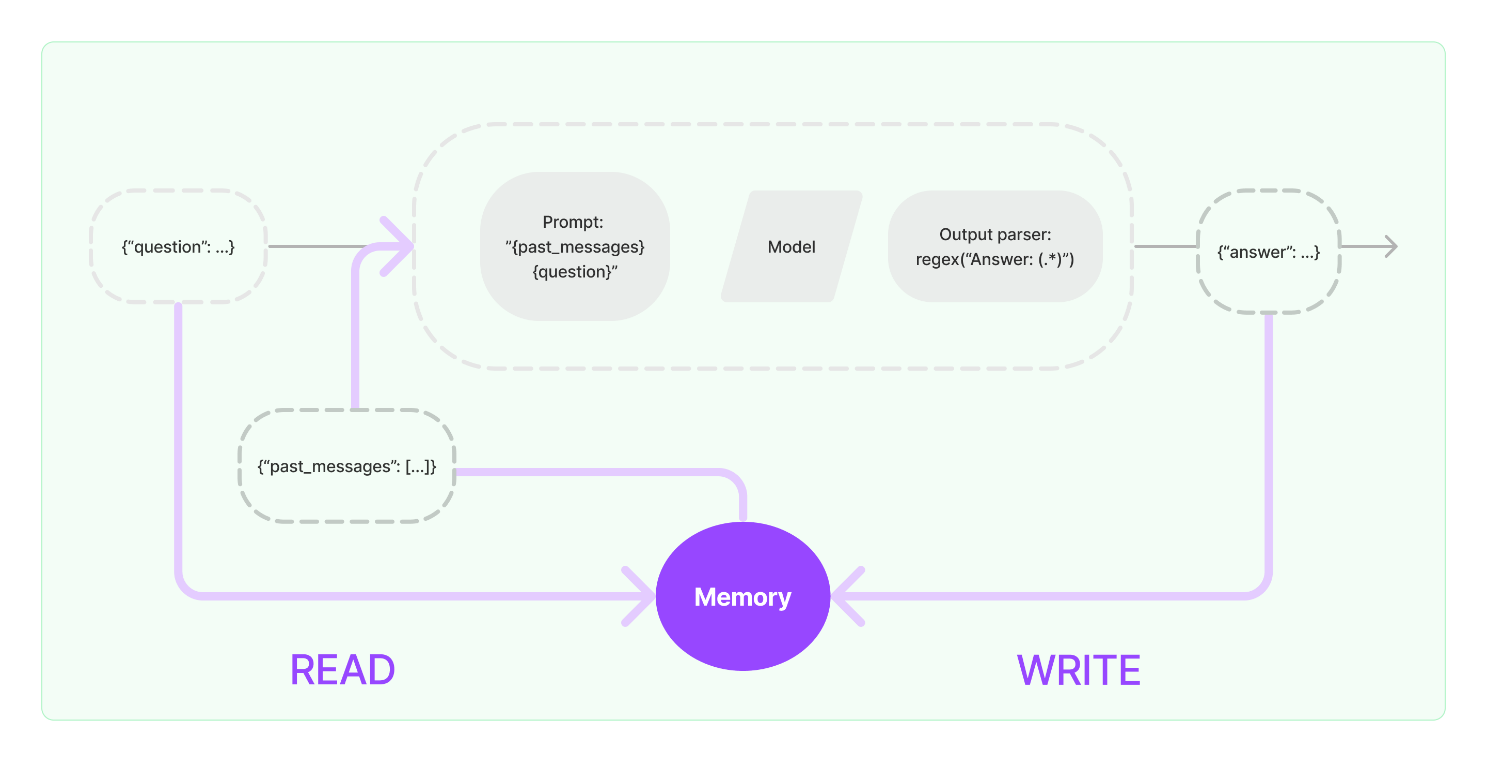 Source: LangChain
Source: LangChain
- Retrieval and Chains
Embeddings and Vector Stores help LangChain understand language nuances, semantic context, and word similarities. This aids in retrieving relevant information for enhanced response generation. Agents are entities within LangChain that facilitate various functions, including understanding user queries, generating responses, and managing interactions. They specialize in different tasks, leveraging models, prompts, and vector information to efficiently perform a wide range of language processing functions. Figure 3 shows the mechanism of vector stores in LangChain.
Figure 3. Vector Stores in LangChain
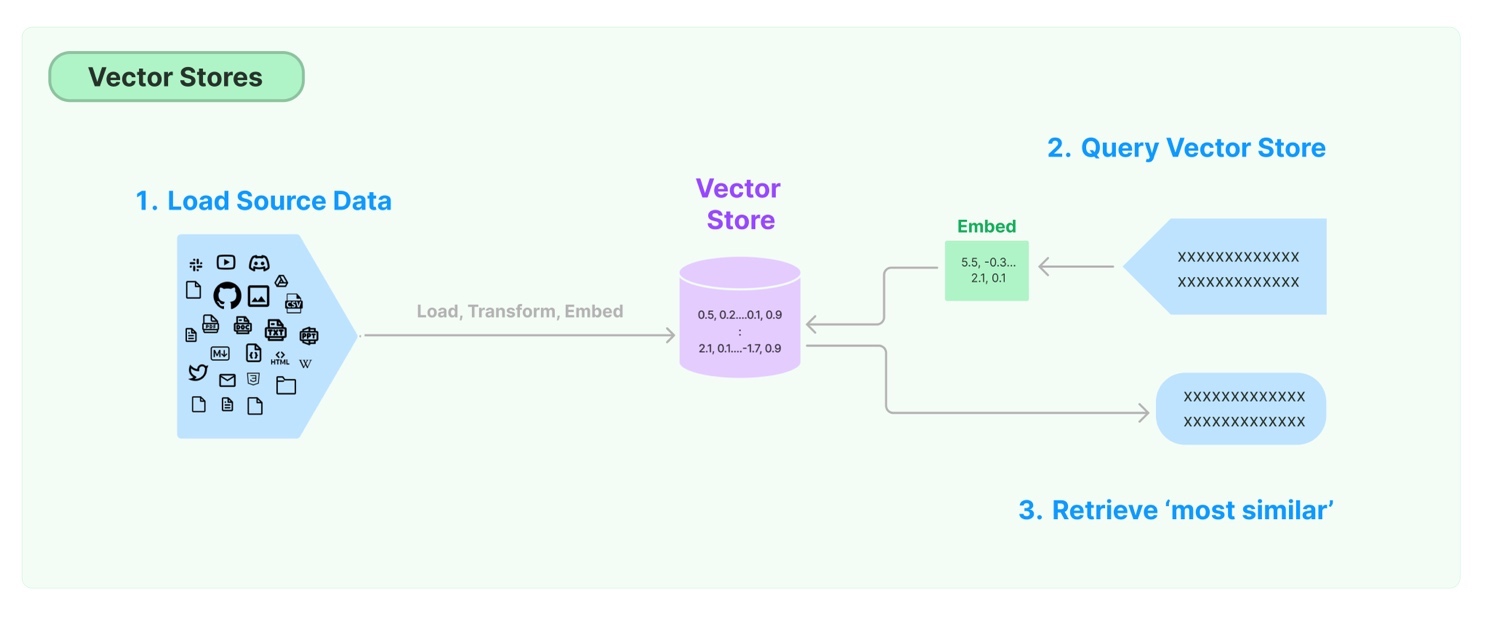 Source: LangChain
Source: LangChain
- Agents
Agent refers to a component that is utilized in certain applications where the chain of actions needed is not predetermined but depends on the user's input. The Agent accesses the tool and determines which specific tool is required based on the user's input and their specific request. A toolkit consists of a collection of tools needed to achieve a particular objective, including 15 types of agent toolkits (e.g. Gmail, Pandas, Github, etc). Unlike LLMs which simply connect to APIs, agents can self-correct, handle multi-hop tasks and tackle long-horizon tasks given vector stores.
There are two primary types of Agents in LangChain, which are Action Agents and Plan-and-Execute Agents. Action Agents make decisions on actions to be taken step by step. They evaluate each step and then execute it before moving on to the next step. Plan-and-Execute Agents evaluate each action to take and then execute all those actions. Figure 4 demonstrates the LangChain agent ecosystem.
Figure 4. LangChain Agent Ecosystem
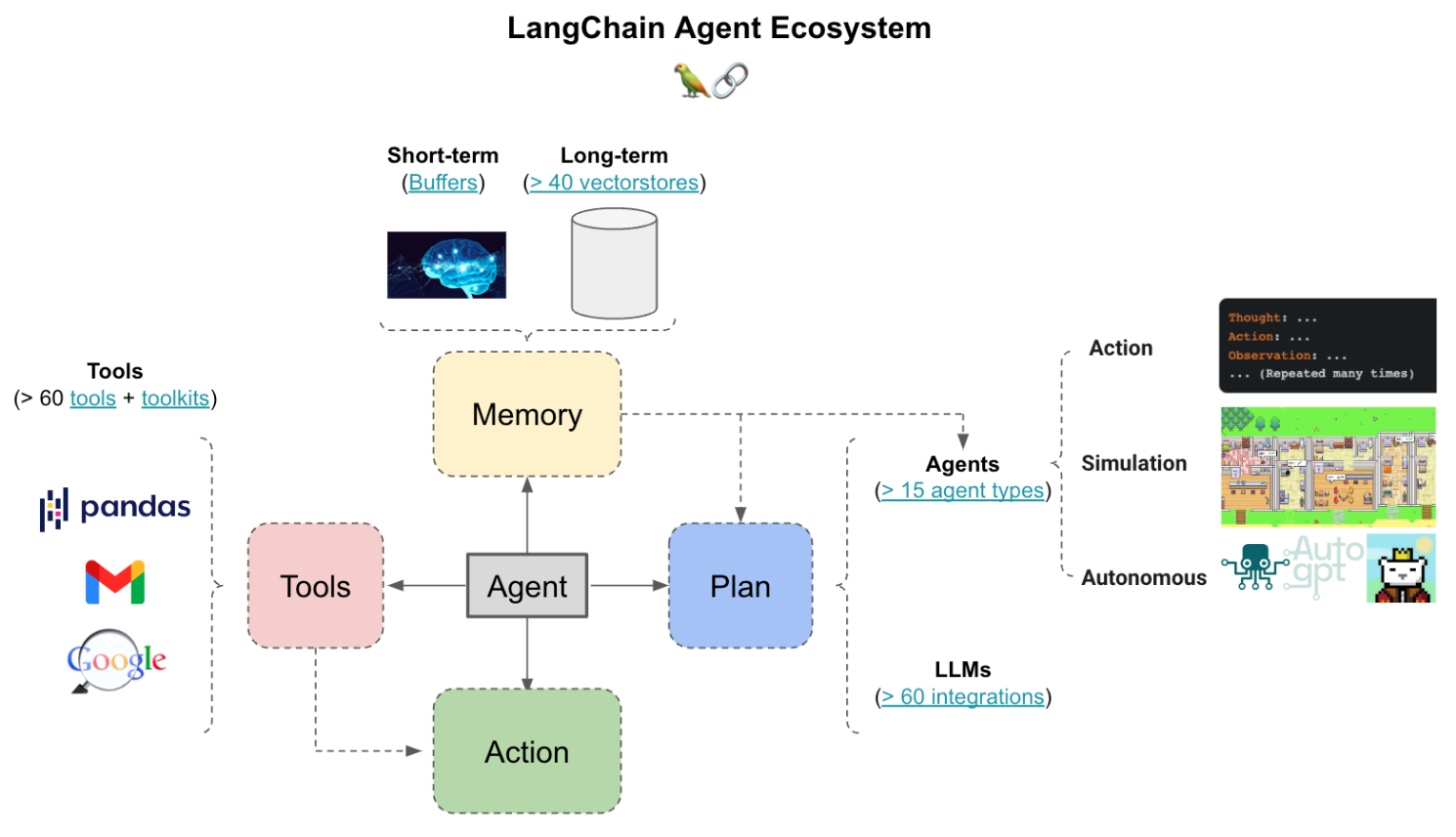 Source: Agents of LangChian
Source: Agents of LangChian
- Callbacks
LangChain offers a callbacks system that enables integration with different stages of your Language Model (LLM) application. This feature proves beneficial for activities like logging, monitoring, streaming, and other related tasks. The callbacks system allows you to seamlessly hook into these stages and perform the desired actions or operations as needed.
A Brief History of Vector Databases
From the late 1990s when the semantic search engine emerged to nowadays when Generative AI and tools such as LangChain adopt vector databases, it propels the development of context-aware knowledge management. Semantic search, the technique behind vector databases, is used in information retrieval to improve the accuracy and relevance of search results by understanding the intent and meaning behind search queries. Traditional keyword-based search engines rely on matching keywords in documents to the search terms, which may not always capture the user's intended meaning. Semantic search goes beyond keyword matching and takes into account contextual understanding, synonyms, related concepts, and the relationship between words. It aims to provide more contextually relevant search results by comprehending the user's query in a more nuanced way.
Semantic search has various methods and technologies, including natural language processing (NLP), machine learning, and knowledge graphs. These techniques enable the search engine to analyze the query, understand the meaning of the words and phrases, and generate more accurate results based on semantic connections. Semantic search can deliver more precise and relevant results, even if the exact keywords are not explicitly present in the documents. It helps users find information more effectively, especially when they are looking for specific answers, exploring complex topics, or seeking information with ambiguous or vague queries. Table 1 illustrates the development of semantic search and vector databases. Table 1 shows the history of vector databases.
Table 1. The Milestone of Semantic Search for Vector Databases
| Time | Milestone | Description |
|---|---|---|
| Late 1990s | Early Approaches to Semantic Search | The concept of semantic search, which focuses on understanding the intent and meaning behind search queries emerged. During this time, search engines began incorporating techniques such as keyword analysis, natural language processing, and information retrieval to enhance search results based on contextual relevance. |
| Early 2000s | Introduction of Vector Space Models | Vector space models gained prominence in the field of information retrieval. These models represented words or documents as vectors in a high-dimensional space, capturing semantic relationships between them. The cosine similarity measure was commonly used to assess the similarity between vectors, enabling more accurate retrieval of relevant information. |
| Mid 2010s | Advancement in Word Embeddings | Word embeddings, which represent words as dense vector representations, gained attention in the mid-2010s. Techniques like Word2Vec and GloVe revolutionized the field by capturing semantic and syntactic relationships between words. These embeddings facilitated more nuanced understanding of language and improved semantic search capabilities. |
| Late 2010s | Evolution of Vector Databases | With the rise of word embeddings, the concept of vector databases emerged. Vector databases store pre-computed vector representations of words, phrases, or documents, allowing for efficient similarity search and retrieval. Systems like Apache Lucene, Annoy, and Faiss were developed to optimize vector storage and retrieval operations, making vector databases a crucial component of semantic search applications. |
| Present | Application of LLMs | Deep learning models, particularly transformer models like BERT and GPT, have significantly advanced semantic search. These models leverage large-scale pre-training on vast amounts of text data to capture complex language semantics and context. By fine-tuning these models on specific tasks, such as question answering or document retrieval, they enable more accurate and context-aware semantic search capabilities. |
Features and Advantages of Vector Databases
Working to the bridge of LLMs, vector databases have entered into a new unified technology proposition. Unlike traditional relational databases that store structured data, vector databases are designed to store high-dimensional data with focus on efficiently storing, indexing, and querying vectors. LangChain serving as a rich source of LLMs. Combining vector databases with LangChain, it enhances the advanced analysis, predictions and decision-making abilities of LLMs. Table 2 shows the features and advantages of vector databases.
Table 2. Features and Advantages of Vector Databases
| Feature | Description |
|---|---|
| Efficient storage and retrieval | LangChain enables LLMs to store and access information from context with strong memory management abilities. Vector databases provide an efficient and optimized storage mechanism for vector representations of the information. It allows LLMs to maintain continuity and coherence in conversations. |
| Similarity-based retrieval | With excellent similarity searches, vector databases can retrieve data that are similar to a given vector. In LangChain, this ability is essential for context matching, entity tracking, and response generation. Backboned by vector databases, LangChain can retrieve relevant vectors that contain similar contexts or entities, helping LLMs to generate more accurate and context-aware responses. |
| World modeling | LangChain integrated with LLMs component that maintains a representation of entities and their relationships. Vector databases can be instrumental in efficiently storing and querying LLMs. LangChain can manage and update vector representations of entities and relationships, facilitating efficient LLMs and enabling the model to reason about the context efficiently. |
| Scalability and performance | Vector databases are designed to handle large of data such as storing large volumes of vectors. LangChain can ensure the retrieval performance. |
| Integration and development | LangChain can integrate with vector databases seamlessly which can store and process a large volume of data in real time. This integration allows LangChain to focus on contextual conversations and optimize model performance |
The Mechanism of Vector Database in LangChain
Vector Stores for Information Processing in LangChain
Vectors are mathematical objects that represent direction and magnitude in space. In LLMs, they are fundamental building blocks for representing complex information in a way that the model can comprehend as shown in figure 5. For example, when a user asks a question, a sophisticated process is employed to ensure accurate comprehension and generation of responses. This process combines the power of a language model and vector representation to achieve optimal results. Vector databases process information and interact with LangChain through the below steps:
- User Query Processing
The user's question is fed into LangChain's language model, which has been extensively trained on diverse text data. The language model's primary objective is to grasp the context, syntax, and semantics of the question, ensuring a thorough understanding.
- Vector Representation
Simultaneously, the question is transformed into a vector representation using advanced vector graph technology. This representation captures the underlying relationships and meanings of the words within the question.
- Similarity Search
The vector representation of the user's question is then utilized to conduct a similarity search within the LangChain database. This database consists of relevant information organized into smaller, vector-based chunks.
- Fetching Relevant Information
The similarity search retrieves the most pertinent chunks of information from the database, closely aligned with the vector representation of the user's question. These chunks contain contextual details that are highly relevant to the question's intent.
- Enhancing Language Model's Knowledge
The retrieved information is fed back into the language model, enriching its understanding of the context. By incorporating both the original question and the pertinent information from the vector database, the language model gains a comprehensive understanding.
- Answer Generation or Action
Equipped with this comprehensive knowledge, the language model is well-prepared to provide accurate answers or take relevant actions in response to the user's query. The combination of the user's question and the supplementary information ensures that the generated response is contextually informed, delivering optimal value in a business context.
Figure 5. The Mechanism of LangChain enabled by Vector Database
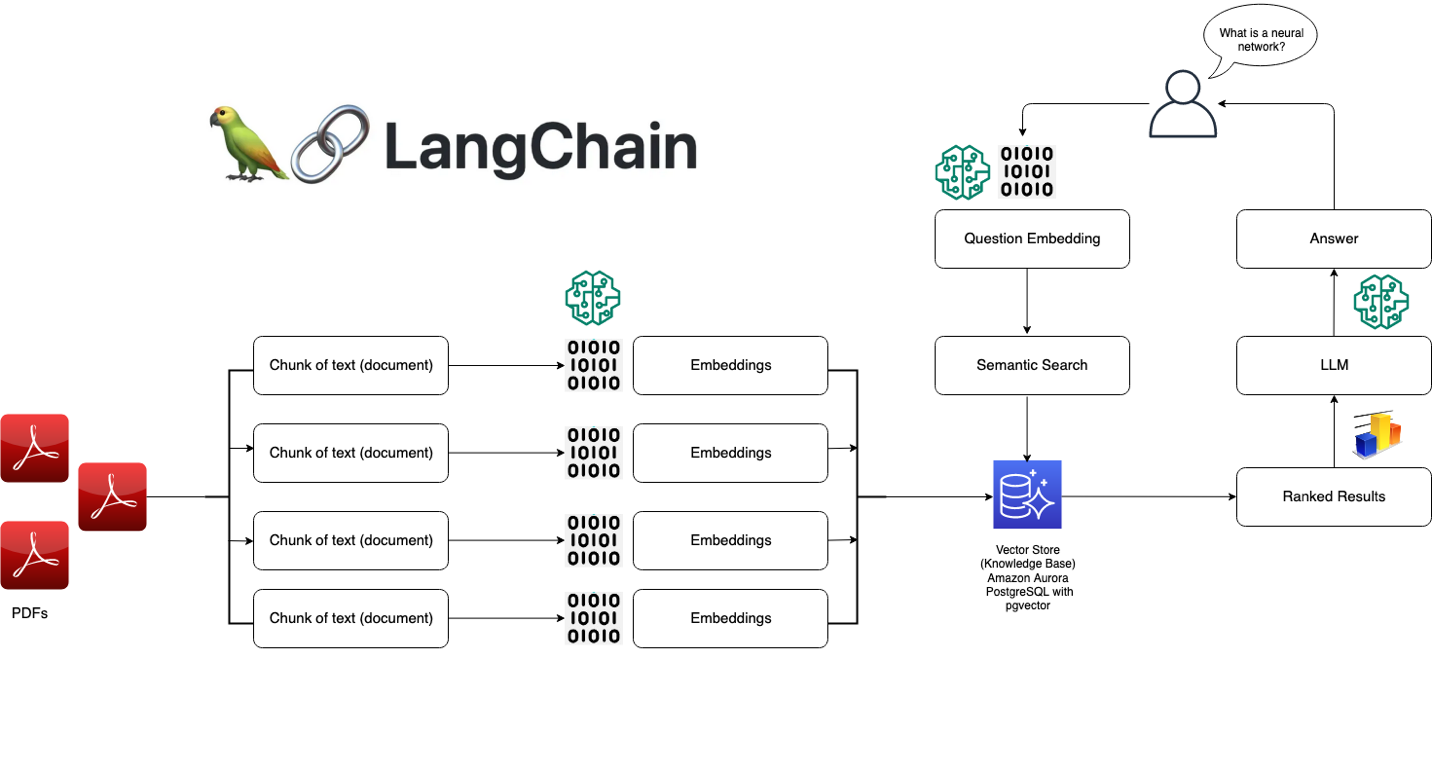 Source: “Leverage pgvector and Amazon Aurora PostgreSQL for Natural Language Processing, Chatbots and Sentiment Analysis”
Source: “Leverage pgvector and Amazon Aurora PostgreSQL for Natural Language Processing, Chatbots and Sentiment Analysis”
Vector Stores for ReAct Agent in LangChain
ReAct, introduced in October 2022 (revised in March 2023) by researchers from Princeton University and Google, synergizes reasoning and acting in language models. The paper explores the interleaved generation of reasoning traces (e.g., chain-of-thought prompting) and task-specific actions (e.g., action plan generation). The researchers highlighted the benefits of this approach, including the model's ability to induce, track, and update action plans with the aid of reasoning traces and handle exceptions, as shown in figure 6. In addition, the model can interface with external sources, such as knowledge bases or environments, to gather additional information through its actions. With chain-of-thought prompting, a sequence of prompts is provided to LLMs. These prompts are interconnected and guide the model through the task. The model is expected to utilize the vector stores from previous prompts to generate the next prompt and achieve the desired outcome.
Figure 6. ReAct (Reason+Act)
 Source: “ReAct: Synergizing Reasoning and Acting in Language Models.”
Source: “ReAct: Synergizing Reasoning and Acting in Language Models.”
Compared to other traditional reasoning methods such as Standard Prompting, Say-Can, and Chain-of-Thought, ReAct takes advantage of multi-step reasoning and action observation, as shown in figure 7.
Figure 7. ReAct Agent and Comparisons
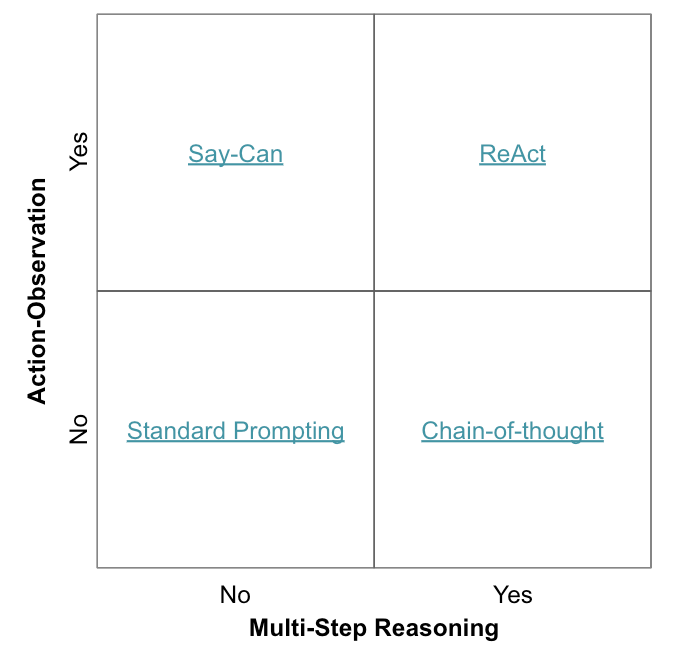 Source: LangChain
Source: LangChain
Business Strategy
Business Model
While LangChain is going viral in the booming market for contextual reasoning, businesses benefit from LangChain and its propeller, such as vector databases that have matured to the point where they offer higher performance search on larger-scale vector data at a lower cost than other potions. To have a look at the current market, while some vector databases commercially benefit from investors and users, many others are open-source.
Open-Source Software as a Service
Open-source Software as a Service, also known as Open SaaS, refers to a software-as-a-service model where the underlying codebase of the SaaS application is open-source and accessible to users. The source code of the software is freely available, allowing users to view, modify, and redistribute the code according to the terms of the applicable open-source license.
Open-source SaaS combines the benefits of cloud-based software delivery (SaaS) with the advantages of open-source software, such as transparency, flexibility, and community collaboration. Users can leverage the SaaS application while also having the ability to customize and extend its functionality to suit their specific needs. In an open-source SaaS model, the provider typically offers a hosted version of the software as a service, but users can also deploy and manage their instances of the software if they prefer. This provides a balance between the convenience of SaaS and the freedom and control offered by open-source software.
Commercial Software as a Service
The commercial SaaS model aims to strike a balance between the principles of open-source software and the need for sustainable business practices. It allows companies to provide a combination of open-source software and commercial offerings to meet the diverse needs of users, while also contributing back to the open-source community through ongoing development, bug fixes, and improvements. The commercial open-source model enables companies to monetize their open-source software by providing value-added services or proprietary extensions. These services may include technical support, consulting, training, customization, maintenance, or hosting. By offering these services, companies can generate revenue while still leveraging the benefits of open-source collaboration and community involvement.
LangChain Applications
By leveraging vector databases, LangChain allows us to tailor for specific use cases. There are four key applications, including summarization, question-and-answer, extraction, and agents. These projects aim to disrupt traditional paradigms and shape new frontiers. It is a testament to the belief that the LangChain has the potential to unlock the possibilities. Although these projects are open-source and experimental, we believe that they are paving the way for groundbreaking advancements and redefining the way we interact with LLMs.
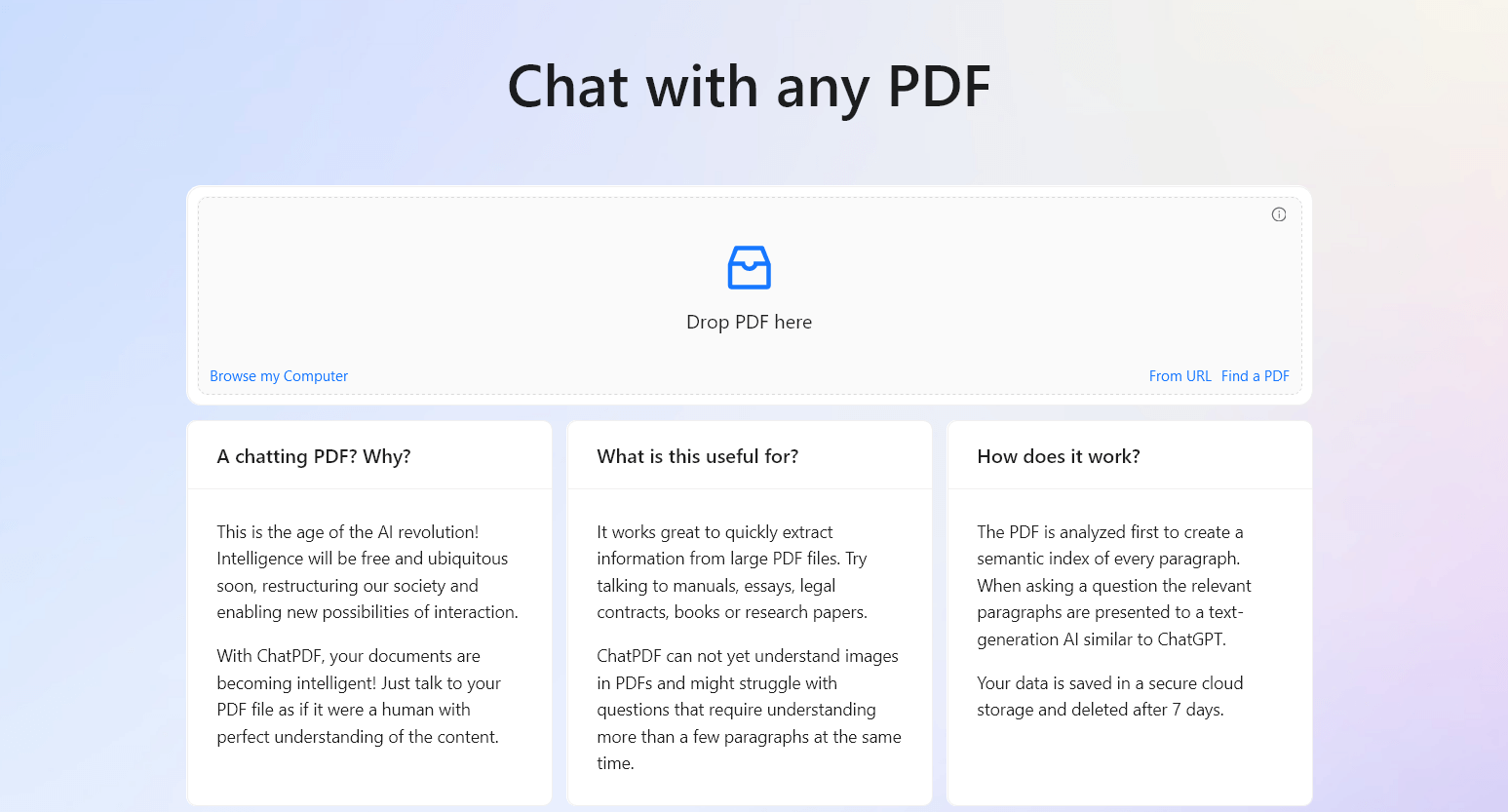
ChatPDF – Chat with PDF using AI
LangChain allows intelligent interaction with text data through its question-and-answer functionality such as ChatPDF (See figure 8). By providing relevant context and specific questions, users can receive accurate and insightful answers tailored to their inquiries, making the process efficient and effective. LangChain also supports the extraction of structured information from text, which is useful when working with APIs and databases. It can extract data for tasks like database insertion or API parameters based on user queries. The built-in library is recommended for advanced schema handling in more complex extraction scenarios. Evaluation is crucial for ensuring the quality of applications that utilize Language Models (LLMs).
Figure 8. ChatPDF
Serper - Summarize Google News Results
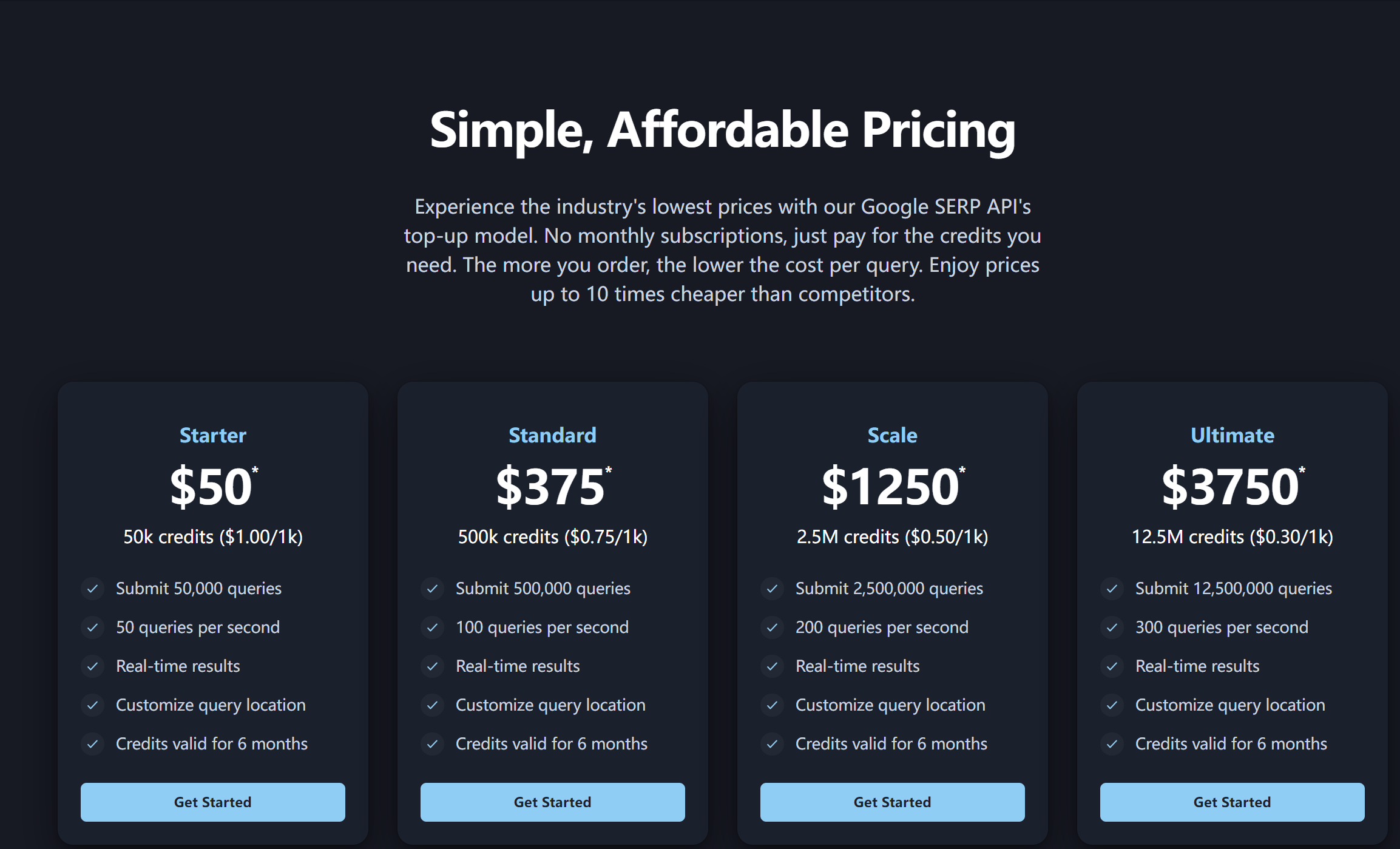
Serper combines LangChain and Serper API to deliver concise summaries of complex news stories. The Serper API fetches relevant Google Search results, and the application goes beyond presenting links and snippets. It retrieves the content from each link and utilizes LangChain to generate a condensed summary of the article. Users benefit from receiving distilled news that captures the essence of the story without the need to sift through extensive content. With Serper API, users can build their own interactive web apps and data visualizations in Python with ease. Serper is subscription-based services, fees ranging from $50 to $3,750 (See figure 9 & 10).
Figure 9. Serper Interface
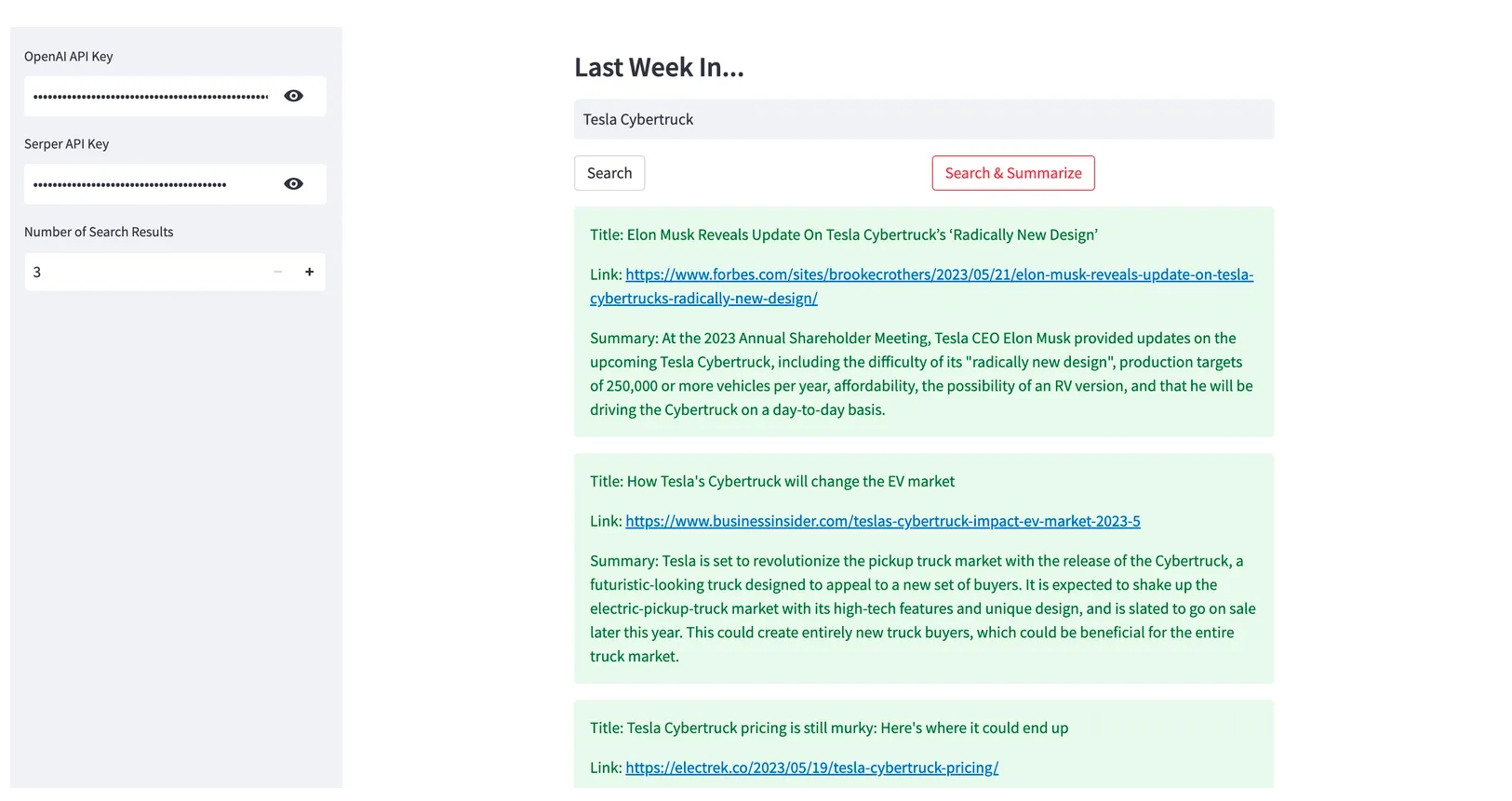
Figure 10. Serper Subscription Plans
Dr. Claude - Revolutionizing Healthcare with LangChain
Dr. Claude is an open-source project that uses the power of LangChain to leverage healthcare as shown in figure 11. It adopts LangChain to construct a Monte Carlo Tree Search (MCTS) for predicting optimal actions during patient-doctor interactions. This advanced technology has the potential to transform healthcare by enhancing decision-making processes (See figure 12). By optimizing patient-doctor interactions, Dr. Claude aims to make healthcare more efficient, effective, and patient-centric, marking a significant breakthrough in the field.
Figure 11. Dr. Claude on GitHub
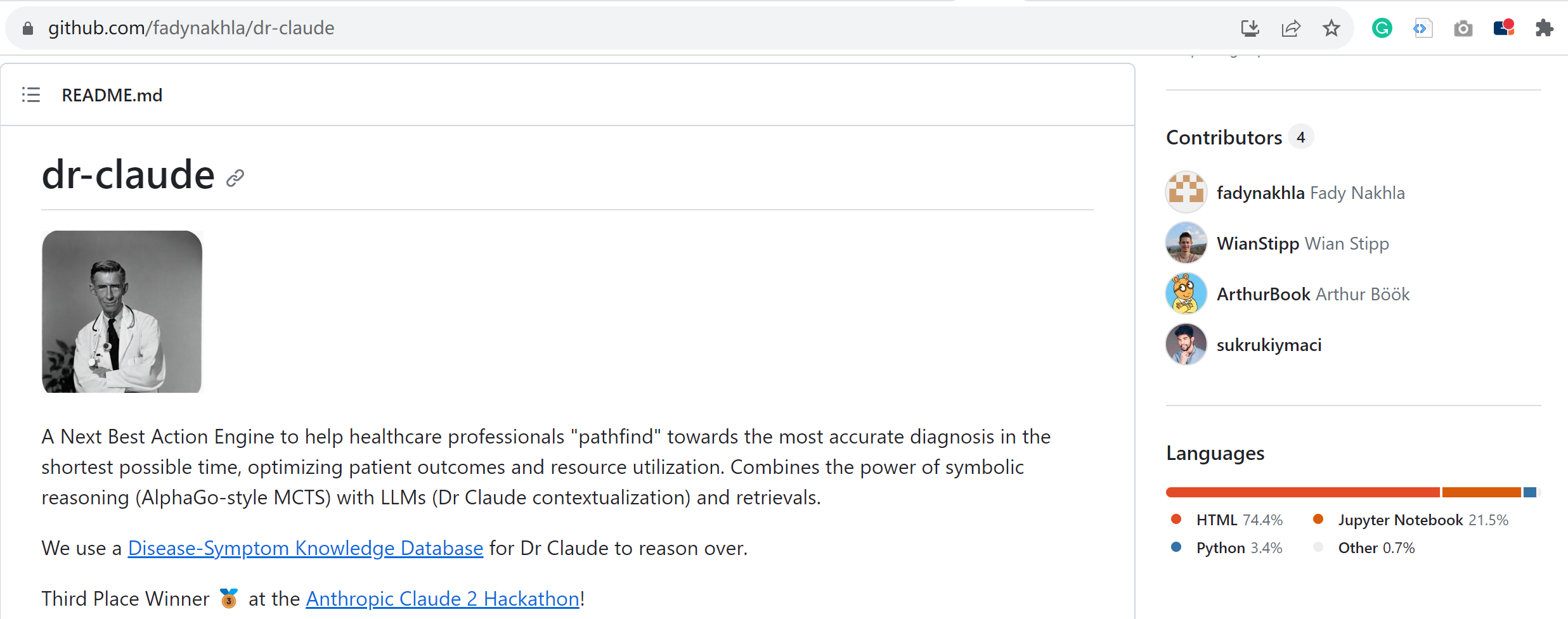 Source: GitHub
Source: GitHub
Figure 12. The flow of LangChain Interacting with LLMs and Vector Database
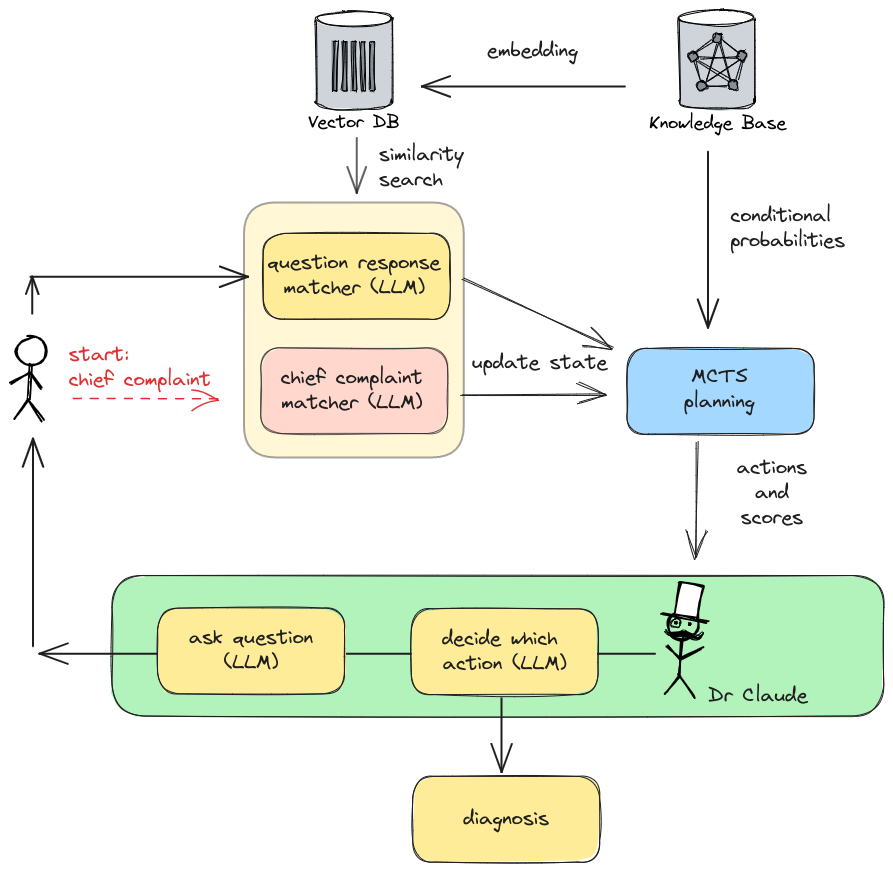 Source: GitHub
Source: GitHub
GPTeam - Exploring LangChain in Multi-Agent Simulations
Agents are decision-making entities that can analyze data, deliberate on the best course of action, and execute actions using various tools. LangChain can serve as agents within LLMs, with the potential to autonomously running programs without human intervention. On 16 May 2023, the release of GPTeam introduced a highly LangChain-enabled open-source multi-agent simulation inspired by Stanford's "Generative Agents" paper. Each agent in GPTeam has a distinct personality, memories, and directives, resulting in fascinating emergent behavior during interactions. GPTeam showcases intricate social behaviors, demonstrating coordination, conversation, and collaboration akin to human interactions (See figure 13 &14). Beyond simulations, GPTeam holds immense potential. It envisions AI agents populating video games, forming authentic emotional connections with players. What’s more, it envisions real-world deployment of multi-agent systems collaborating to tackle complex challenges. GPTeam opens up possibilities for immersive gaming experiences and real-world problem-solving.
Figure 13. GPTTeam – Collaborative AI Agents on Guthub
 Source: GitHub
Source: GitHub
Figure 14. Multi-agent Architecture of GPTeam
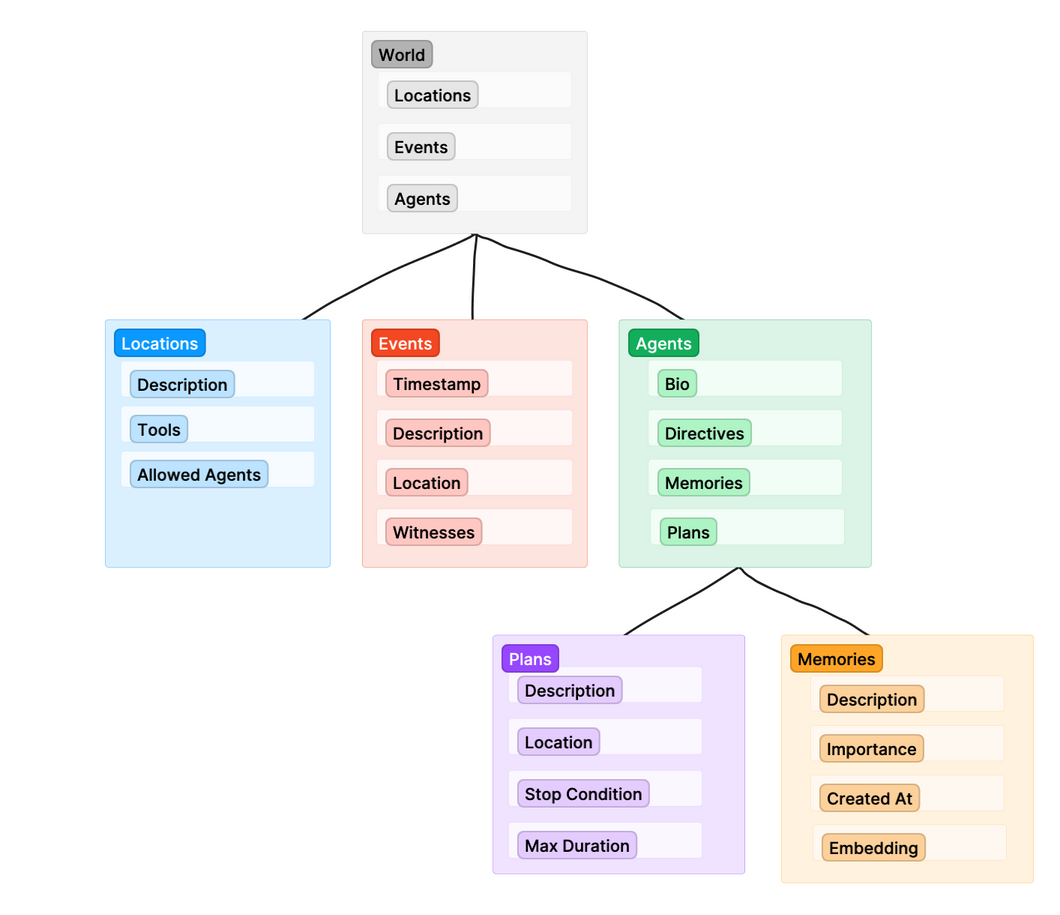 Source:GitHub
Source:GitHub
Market Landscape
Market Size
LangChain is an open-source framework that has gained significant attention and popularity since April 2023. It has gained over 64.1k stars on Github as of October 2023, as shown in figure 15. This surge in popularity suggests that LangChain has attracted a large community of developers and users who find value in its features and capabilities.
Figure 15. Star History of LangChain
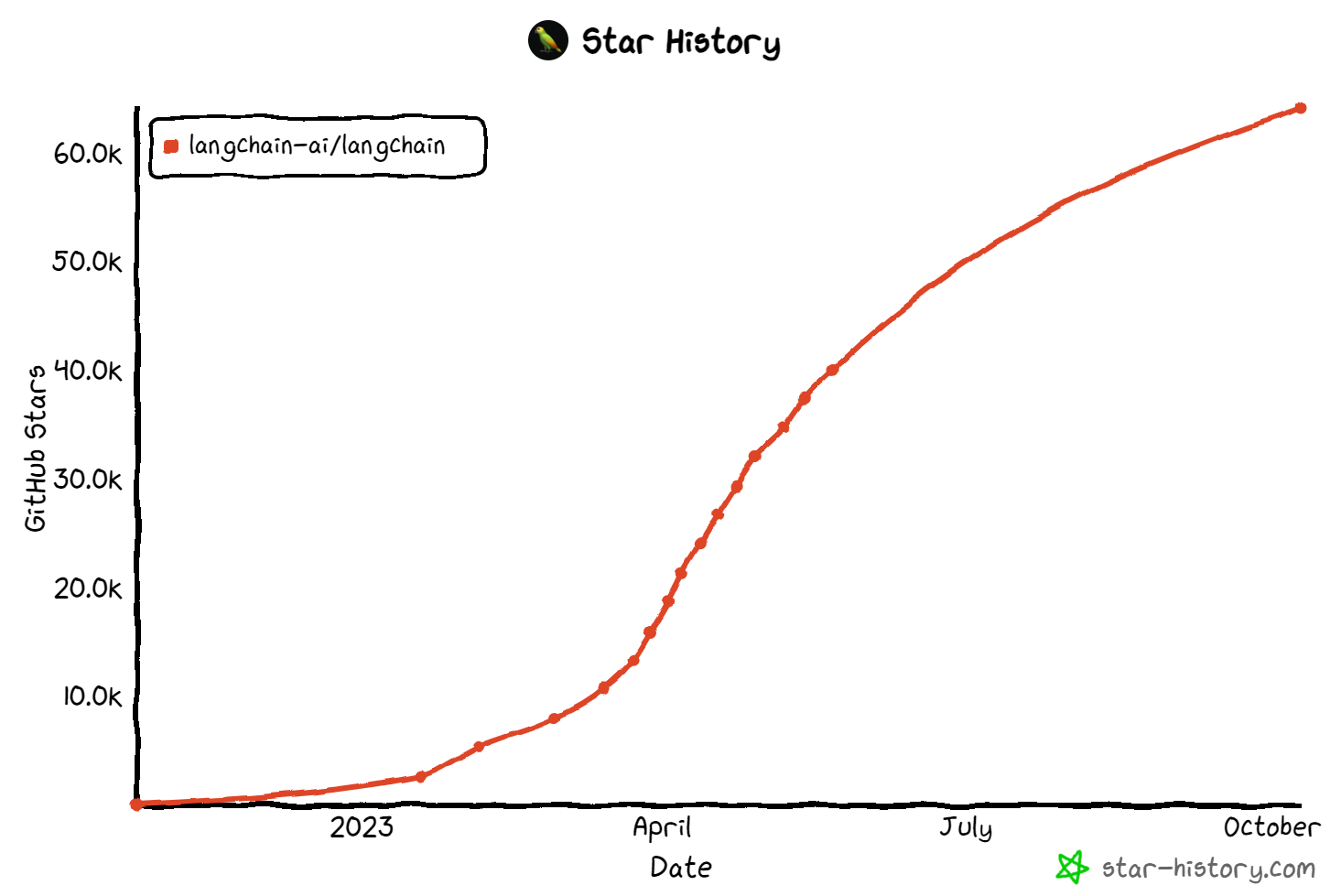 Source: GitHub Star History
Source: GitHub Star History
On the other hand, vector databases, the propeller of LangChain, also witnessed a soar in 2023. Around 80% of the generated data will be unstructured by 2025, ranging from images and videos to protein structures. Vector databases offer an easy way to store, search, and index unstructured data at a speed, scale, and efficiency that relational databases cannot offer. This is particularly useful for “similarity search”, such as enhancing generative AI for searching similar images, suggesting similar videos and improving contextual awareness of long domain-specific applications. The global vector database market size is projected to increase from USD 1.0 billion in 2021 to USD 2.5 billion by 2026. This growth is expected to occur at a Compound Annual Growth Rate (CAGR) of 20.2% throughout the forecast period. In addition, it is expected that the current adoption rate of vector databases at 6%, with a projected increase to 18% over the next 12 months.
The vector database markets in North America and Europe are experiencing steady growth. This growth is attributed to government initiatives and increasing consumer awareness of vector databases in these regions. In North America, government initiatives may include investments in data infrastructure, smart city projects, or other initiatives that require efficient storage and analysis of vector data. Increasing consumer awareness suggests that businesses and organizations in North America are recognizing the value and potential applications of vector databases for their operations.
Similarly, in Europe, government initiatives and growing consumer awareness are driving the growth of the vector database market. These initiatives may involve promoting digital transformation, supporting data-driven innovation, or implementing geospatial projects that require the use of vector databases. In the Asia-Pacific region, particularly in China, the vector database market is reported to be leading globally. This is attributed to robust domestic demand, supportive policies, and a strong manufacturing base. The growing demand for vector databases in China could be driven by various factors, such as infrastructure development, urban planning, logistics optimization, or other applications that rely on geospatial data.
Market Map
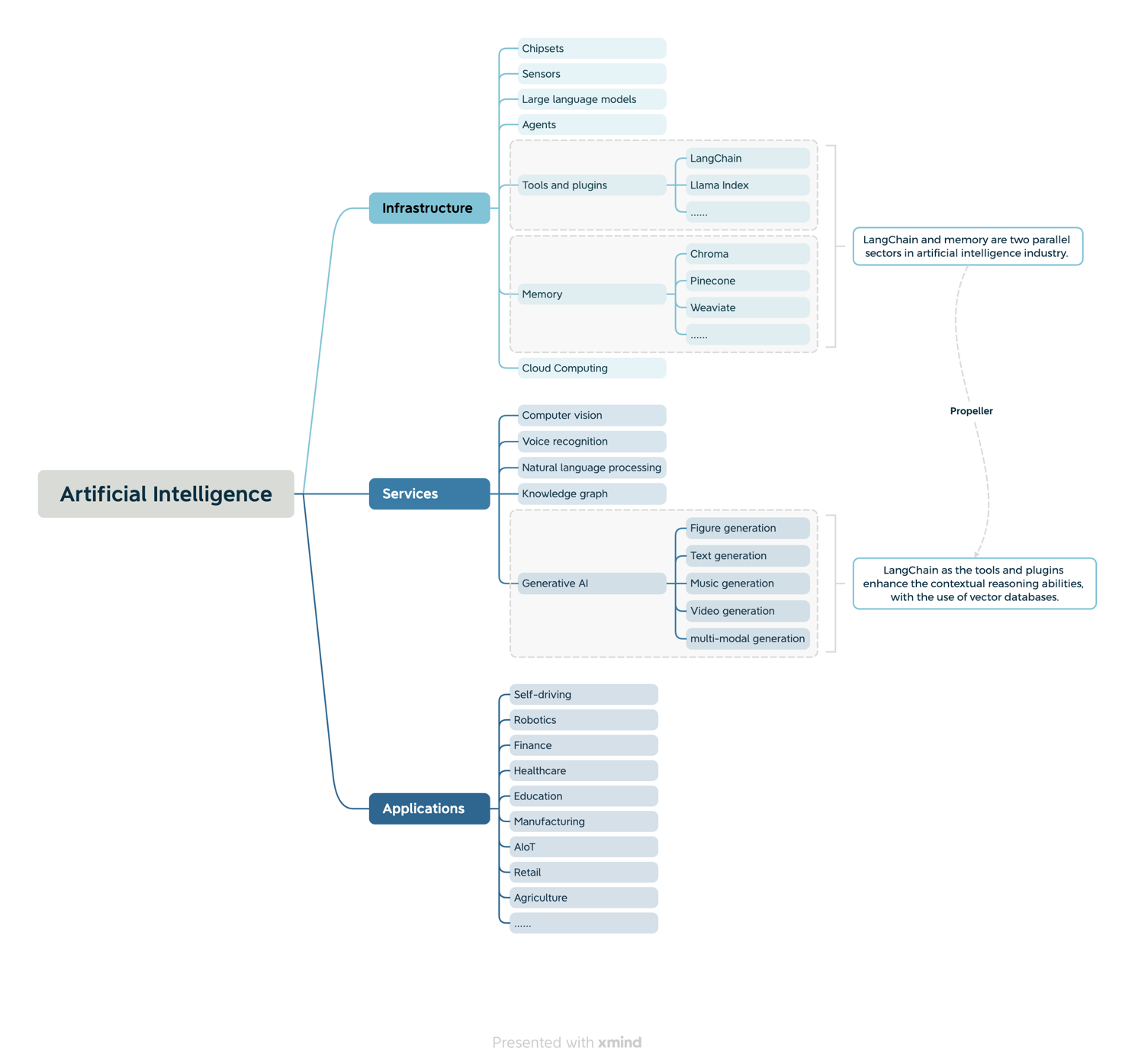
LangChain and vector databases play integral roles in the artificial intelligence sector, functioning as essential tools and plugins as well as memory components as shown in figure 16. They form the infrastructure that powers the advancements in artificial intelligence. LangChain serves as a comprehensive suite of tools and plugins, offering a wide range of functionalities and capabilities that enable developers and researchers to build and deploy powerful generative AI models. It provides the necessary frameworks and resources to enhance contextual reasoning and domain-specific understanding, enabling LLMs to generate more accurate and contextually relevant outputs. On the other hand, vector databases act as the memory that stores and organizes vast amounts of data efficiently. They facilitate efficient vector computation and similarity search based on inverted indexes, allowing AI models to retrieve and analyze relevant information quickly. By leveraging vector databases, LLMs can access and process large datasets with ease, enhancing their comprehension and reasoning abilities.
LangChain and vector databases form a symbiotic relationship, propelling the field of generative AI forward. LangChain provides the tools and frameworks necessary to develop sophisticated AI models, while vector databases optimize the storage and retrieval of data, enabling efficient processing and reasoning. This combination enables LLMs to make significant strides in contextual reasoning, pushing the boundaries of what is possible in natural language understanding and generation.
As the artificial intelligence industry continues to evolve, LangChain and vector databases will remain vital components of the infrastructure, driving advancements and fueling breakthroughs in generative AI. Their complementary roles as tools and memory components ensure a robust and efficient ecosystem for developing and deploying advanced AI applications. The ongoing development and integration of these technologies will contribute to the continued growth and innovation in the field of artificial intelligence.
Figure 16. LangChain and Vector Databases Market Segment
LangChain is an all-in-one solution that brings together different tools and libraries. Its core principles are modularity and composability, which resemble universal API providers. In this context, LangChain acts as a “glue” or “connector” that brings the functions and base LLMs and APIs together. LangChain provides ready-to-use tools and libraries that cover the entire process, from preprocessing unstructured data (e.g., UnstructuredIO, Airbyte) to evaluating results from different models. It also adds memory management by linking vector databases (e.g., Pinecone, Weaviate, Zilliz) with agents and external knowledge base. Those companies include Wikipedia, Wolfram Alpha, and Zapier. LangChain also adds an additional layer on top of LLMs, allowing users to easily switch between various LLMs, agents, and vector databases, which can help mitigate risks associated with relying on a single LLM. With the use of PromptBase, PromptLayer, it can easily enhance accuracy and long-context reasoning. Figure 17 demonstrates the LangChain ecosystem.
Figure 17. LangChain Ecosystem

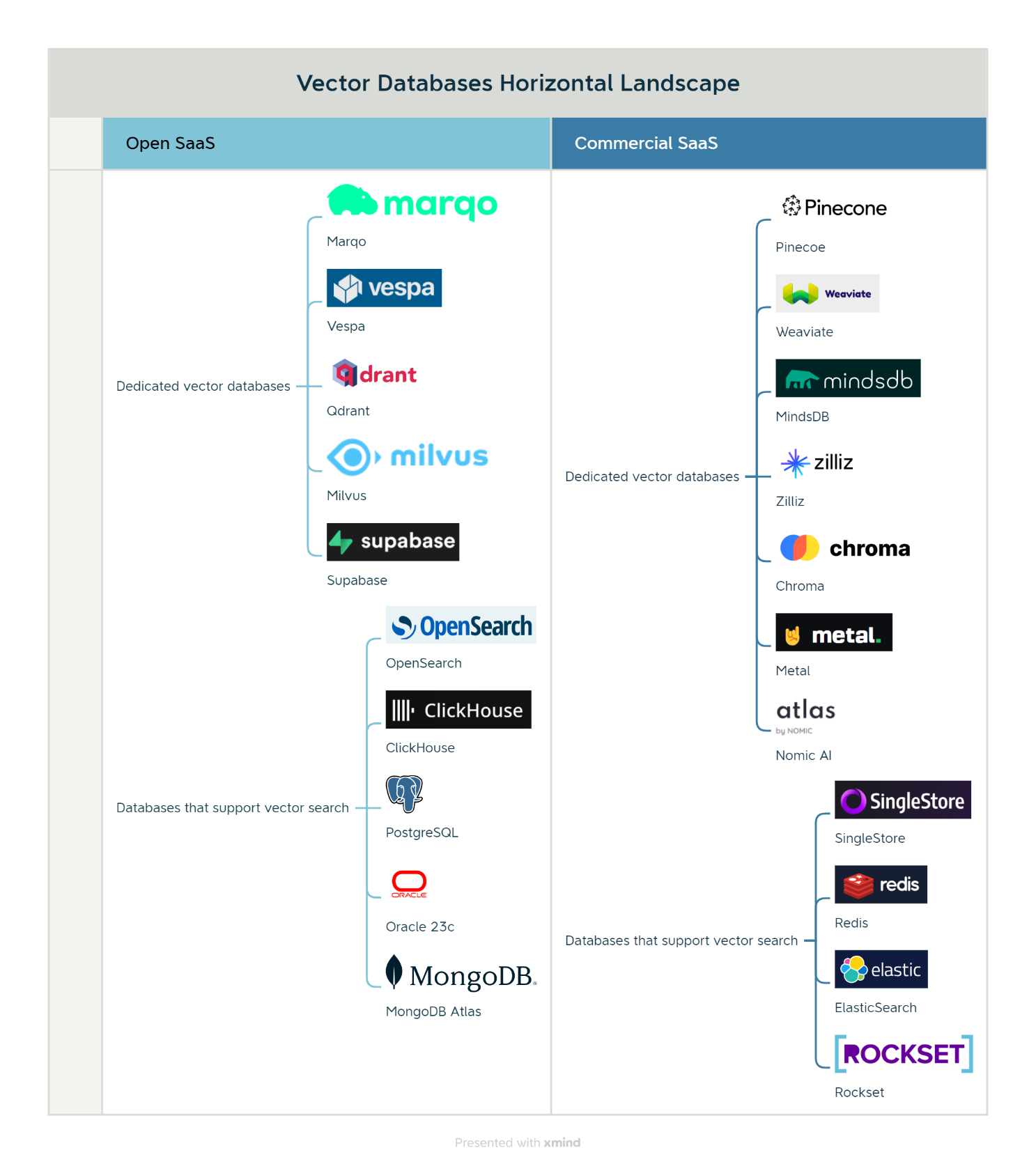
Vector databases offer several important data management functions including metadata storage, real-time data changes, granular access control, resource allocation for performance, concurrency management, and elastic scalability. Seeing the vector database sector from a horizontal perspective, as shown in figure 18, we may notice that existing relational database service providers such as PostgreSQL, Oracle are also delving into vector databases by customizing their services to meet the LLMs market needs. Vector databases can be classified into two types, including dedicated vector databases and databases that support vector search. Dedicated databases such as Chroma, Pinecone and Marqo are specifically designed for scaling to handle billions of vectors. They offer optimized storage and query functions for vector embeddings. Many businesses are using dedicated vector databases for generative AI applications and have provided positive feedback on their usage. While extended vector databases are not natively support vectors but provide vector indexes and functions to enable vector processing. Users of extended vector databases can leverage their existing databases to integrate and manage traditional structured and unstructured data with high-dimensional vectors to support semantic search on LLMs. It is expected that most traditional databases will incorporate some level of vector processing functions in the future.
Figure 18. Vector Databases Horizontal Landscape
Company Analysis
Summary
The global spending on AI technology and services is projected to reach $154 billion in 2023 and surpass $300 billion in 2026. This growth will be fueled by a new type of data called embedding vectors, which are AI-generated representations of various objects. Vector databases have recently gained significant attention in the AI market. For example, Pinecone announced a $100 million Series B investment on a $750 million post valuation. This reflects the growing interest in the infrastructure software that supports AI applications. While AI applications have been in the spotlight for a while, the importance of robust and efficient infrastructure, like vector databases, is now being recognized. By looking into tech giants. Oracle, PostgreSQL and MongoDB are also released their extensions to enhance vector search, while startups such as Pinecoe, Weaviate, Chroma gain more popularity in the vector database sector. In the table, we have witnessed $1.39 billion funding, and we expect to gain momentum. Table 3 shows the top-funded startups.
In the following sections, we will explore the reasons behind the increased attention on vector databases and provide a comparison of current alternatives in this space.
Table 3. Top-funded Startups
| Company Name | About | Lead Investors | Last Funding Status | Last Funding Date | Last Funding Amount | Total Funding Amount | GitHub Stars | Open Source | Business Model | Location |
|---|---|---|---|---|---|---|---|---|---|---|
| Chroma | Chroma operates as an AI-native open-source embedding database. | Quiet Capital | Seed | Apr 06, 2023 | $18M | $20.3M | 4.4k | Y | Commercial SaaS | San Francisco Bay Area, West Coast, Western US |
| ClickHouse | ClickHouse is a developer of an online analytical processing (OLAP) database management system. | Thrive Capital | Early Stage Venture | Dec 06, 2022 | - | $300M | 31.1k | Y | Commercial SaaS | San Francisco Bay Area, West Coast, Western US |
| DataStax | DataStax is the real-time data company for Gen AI applications. | GS Growth | - | Jun 15, 2022 | $115M | $342.57M | N/A | N | Commercial SaaS | San Francisco Bay Area, Silicon Valley, West Coast, Western US |
| LangChain | LangChain is a language model application development library. | Benchmark | Seed | Mar 20, 2023 | $10M | $10M | 64.1k | Y | Open SaaS | San Francisco Bay Area, West Coast, Western US |
| Marqo | A tensor-based search and analytics engine that seamlessly integrates with your applications, websites, and workflows. | Blackbird Ventures | Seed | Aug 16, 2023 | $5.2M | $5.93M | 2.8k | Y | Commercial SaaS | Asia-Pacific (APAC), Australasia |
| SingleStore | SingleStore is a provider of a database for operational analytics and cloud-native applications. | Goldman Sachs, Prosperity7 Ventures | Late Stage Venture | Oct 03, 2022 | $30M | $464.1M | N/A | N | Commercial SaaS | San Francisco Bay Area, West Coast, Western US |
| Metal | Metal is a developer platform that provides APIs and models to build AI products. | Swift Ventures | Seed | Jun 22, 2023 | $2.5M | $3M | N/A | N | Commercial SaaS | Greater New York Area, East Coast, Northeastern US |
| MindsDB | MindsDB is an open-source platform that enables developers to integrate machine learning into applications. | NVentures | Seed | Aug 08, 2023 | $5M | $54.36M | 18.1k | Y | Commercial SaaS | San Francisco Bay Area, West Coast, Western US |
| MongoDB | MongoDB is a next-generation database that helps businesses transform their industries by harnessing the power of data. | Salesforce | Ipo | Mar 06, 2018 | - | $311M | - | - | - | Greater New York Area, East Coast, Northeastern US |
| Nomic AI | Nomic AI engages in improving both the explainability and accessibilty of AI. | Coatue | Early Stage Venture | Jul 13, 2023 | $17M | $17M | N/A | Y | Commercial SaaS | Greater New York Area, East Coast, Northeastern US |
| Oracle | Oracle is an integrated cloud application and platform services that sells a range of enterprise information technology solutions. | Sequoia Capital | Ipo | Jan 01, 1983 | - | - | - | - | - | Southern US |
| Pinecone | Pinecone develops a vector database that makes it easy to connect company data with generative AI models. | - | Early Stage Venture | Nov 01, 2023 | - | $138M | N/A | N | SaaS | Greater New York Area, East Coast, Northeastern US |
| PostgreSQL | PostgreSQL is an object-relational database management system with an emphasis on extensibility and standards-compliance. | - | - | - | - | - | - | - | - | Greater Philadelphia Area, Great Lakes, Northeastern US |
| Qdrant | Qdrant is an open-source vector search engine and database for next-generation AI applications. | Unusual Ventures | Seed | Apr 19, 2023 | $7.5M | $9.79M | 6.6K | Y | Open SaaS | European Union (EU), Europe, Middle East, and Africa (EMEA) |
| Supabase | Supabase is an open-source Firebase alternative that provides a full PostgreSQL database. | Felicis | Early Stage Venture | May 10, 2022 | $80M | $116.12M | 57.7k | Y | Open SaaS | San Francisco Bay Area, West Coast, Western US |
| Weaviate | Weaviate develops an open-source vector database. | Index Ventures | Early Stage Venture | Apr 20, 2023 | $50M | $67.7M | 5.6k | Y | Open SaaS | European Union (EU), Europe, Middle East, and Africa (EMEA) |
| Zilliz | Vector Database for Enterprise-grade AI | Prosperity7 Ventures | Early Stage Venture | Aug 24, 2022 | $60M | $113M | N/A | N | Commercial SaaS | San Francisco Bay Area, West Coast, Western US |
| Total Funding | $400.2M | $1.97B | ||||||||
Listed Companies
Oracle Database 23c
Since Oracle Database 23c has been released in April 2023, Oracle has announced its plans to enhance 23c with semantic search using AI vectors. This update introduces new vector data types, vector indexes, and vector search SQL operators, enabling the database to efficiently store and retrieve semantic content from various data types such as documents and images. The addition of AI vectors is expected to significantly improve data retrieval processes by enabling lightning-fast similarity queries.
Oracle also aims to democratize access to natural language processing capabilities by incorporating LLM-based natural language interfaces into applications built on Oracle Database and Autonomous Database. This enables end-users to query data using everyday language, making data access simpler and more intuitive. Furthermore, Oracle's data integration and data mesh solution, GoldenGate 23c Free, will be available for free, offering a simplified user experience to cater to individuals with limited experience.
PostgreSQL pgvector
PostgreSQL is a reliable and high-performance relational database system that is available as an open-source solution. It has a strong track record of over 35 years of active development, which has contributed to its reputation for dependability and robustness. One of the advantages of PostgreSQL is its extensibility. It comes with a wide range of modules and extensions developed by contributors within the PostgreSQL community. These components are maintained by the community and can be utilized through the creation of extensions.
In September PostgreSQL released pgvector 0.5.0 version of extension for vector similarity search. It can also be used for storing embeddings. It features for the exact and approximate nearest neighbors, L2 distance, inner product distance, and cosine distance for each language that has a Postgres client.
MongoDB Atlas
MongoDB Atlas offers several powerful features for building advanced applications. Atlas Vector Search enables AI-powered search and personalization, while Atlas Search Nodes provide dedicated infrastructure for scaling search workloads. Atlas Stream Processing simplifies the analysis of high-velocity streaming data. Time Series collections offer improved scalability and flexibility for time series workloads. Atlas Online Archive and Data Federation now support both AWS and Azure. The LangChain framework enhances app development using large language models, and MongoDB has collaborated with LangChain to drive community integration.
Startup Companies
Pinecone
Pinecone, a vector database company, has announced a $100 million Series B investment, valuing the company at $750 million in April 2023. Pinecone initially launched its vector database in 2021, targeting data scientists, but has since expanded its focus to AI-driven semantic search. The growing awareness and adoption of large language models (LLMs) have increased the recognition of the value of vector databases. Pinecone has positioned itself as a leader in this emerging category and has experienced rapid growth, with its customer base expanding from a few customers to 1,500 within a year. The company has attracted interest from various businesses, including technology companies like Shopify, Gong, and Zapier.
The CEO and founder of Pinecone, Edo Liberty, attributes the company's success to being the first in the market and emphasizes the flexibility and efficiency of its vector database compared to LLMs. While both LLMs and vector databases enable searching large amounts of data, LLMs have the data embedded in the model, making them less flexible, whereas vector databases are designed for semantic search and offer the flexibility of a database. Liberty highlights the vector database's advantages in terms of compliance, such as GDPR, where removing records is easier in a database structure than in a model. The solution processes data quickly, and supports metadata filters and sparse-dense index for high-quality relevance, guaranteeing speedy and accurate results across a wide range of search needs.
Peter Levine of Andreessen Horowitz, who led the recent investment and will join the Pinecone board, sees the vector database as a crucial component of the AI data stack. He believes that Pinecone, with its vector database, can address the "hallucination problem" associated with LLMs by providing a source of truth. Levine envisions the vector database working alongside LLMs, serving as long-term memory and supplying information for more precise answers.
Chroma
San Francisco-based database provider Chroma Inc. has secured $18 million in seed funding in April 2023. The investment was led by Quiet Capital, with participation from executives at Hugging Face Inc. and several other tech companies. Chroma, led by CEO Jeff Huber, has developed an open-source database specifically designed to support artificial intelligence (AI) applications. Since its launch less than two months ago, the database, also called Chroma, has been downloaded over 35,000 times.
Chroma's database focuses on storing AI models' embeddings, which are abstract mathematical structures representing data in the form of vectors. Embeddings allow AI models to identify similarities and dissimilarities between data points, enabling tasks such as recommendation systems and cybersecurity detection. Traditional databases are not optimized for storing embeddings, making Chroma's database a valuable tool for developers working with AI models. It provides a simplified developer experience, reduces manual work, and supports various embedding generation algorithms, including commercial tools like OpenAI LLC's service.
To enhance performance, Chroma offers an in-memory mode that keeps information in RAM from the start, speeding up computations by eliminating the need to retrieve data from storage. With the new funding, Chroma plans to develop new features, including the ability to determine the relevance of retrieved information to specific queries. Additionally, the company is working on a commercial, managed version of its database, scheduled for launch in the third quarter.
Zilliz
Chinese startup Zilliz, known for its open-source vector database Milvus, has secured $60 million in funding as it expands its operations to the United States in August 2023. The funding round was led by Prosperity7 Ventures, with participation from existing Chinese investors such as Temasek's Pavilion Capital, Hillhouse Capital, 5Y Capital, and Yunqi Capital. This latest funding brings Zilliz's total raised capital to $113 million. The company's move to San Francisco reflects the increasing demand for more efficient data processing techniques for unstructured data used in AI applications. Zilliz's Milvus database has gained popularity, with over 1 million downloads and notable customers such as eBay, Tencent, Walmart, Ikea, Intuit, and Compass. The funding will support Zilliz's roadmap, which includes the development of new products, such as the Zilliz Cloud-managed service and Towhee, an open-source framework for vector data ETL.
Vector databases like Milvus are particularly well-suited for AI applications due to their ability to process complex AI data representations efficiently. Zilliz aims to provide a fully managed vector database service with security, reliability, ease of use, and affordability for enterprises. The company faces competition from other players in the market, including Pinecone and Weaviate, as well as offerings from large cloud providers like AWS.
Weaviate
Weaviate.io, the developer of the AI-native Weaviate vector database, has announced a $50 million round of funding led by Index Ventures, with participation from Battery Ventures in April 2023. Existing investors, including NEA, Cortical Ventures, Zetta Venture Partners, and ING Ventures, also joined the round. The funding will be used to expand the Weaviate team and accelerate the development of its open-source database and new Weaviate Cloud Service, catering to the rapidly growing AI application development market.
The Weaviate database simplifies vector data management for AI developers, offering extensible machine learning modules, richer vector search capabilities, and high performance. Since its series A funding in early 2022, Weaviate has surpassed 2 million open-source downloads. The company has also launched the Weaviate Cloud Service, providing developers with the full power of the Weaviate database without operational overhead. The service is available immediately and offers a 14-day free trial.
Weaviate's vector database and search engine are considered critical infrastructure components driving the shift in the AI platform. The company's partnership with Index Ventures and Battery Ventures aims to drive the next phase of growth in enterprises and AI-native startups developing multimodal search, recommendation, and generative applications. Weaviate has introduced generative search support, making it easier for developers to leverage large language models like GPT-4 for meaningful interactions in natural language. The company believes it is poised to lead the revolution of vector databases, providing organizations with essential tools for storing, indexing, and retrieving unstructured data through vector embeddings.
Outlook and Challenges at a Glance
Outlook
The outlook for vector databases in generative AI is promising, as they offer several advantages and address specific challenges in context-specific domains. Vector databases enable efficient storage, indexing and retrieval of high-dimensional vector data, which is crucial in long-context comprehension and reasoning. Sorting and processing large amounts of vector data efficiently allows for faster training and inference, leading to improved efficiency in generative AI workflows. This is particular important for recommendation systems where vector databases can enhance similarity matching, personalized recommendations and efficient real-time updates. In terms of contextual comprehension and reasoning, vector databases play a crucial role in semantic search, document similarity, text classification, and entity recognition. They can efficiently store and retrieve word or sentence embeddings, enabling fast and accurate search and retrieval.
Taking advantage of open SaaS, many vector databases can customize, extend, and integrate LLMs through APIs. Open SaaS gives the flexibility to tailor the vector databases to specific needs. They can customize and configure the software’s functionality, user interface, workflows, and integrations to align with their unique requirements. Open SaaS also fosters a vibrant developer ecosystem around the platform. By providing open APIs and developer-friendly tools, the SaaS provider encourages developers to build integrations, extensions, and custom applications on top of the platform. This ecosystem promotes innovation, as developers can leverage the SaaS platform's core capabilities to create new functionalities and address specific business needs. Open SaaS promotes the customizable and fast-changing needs of generative AI industry.
Challenges
There are several drawbacks to the Open SaaS business model. Organizations rely on the SaaS provider for the hosting, maintenance and update, which can result in a loss of control over important aspects such as infrastructure and performance optimization. In addition, the source codes are available for everyone to edit. Open SaaS solution raises concerns about data governance, privacy, and security. Organizations need to carefully evaluate the provider's data security measures, encryption protocols, access controls, and compliance with relevant regulations to ensure data protection and minimize the risk of data breaches or unauthorized access.
Open SaaS has also raised concerns within the open-source community regarding the sustainability of original creators and maintainers. While many vector database companies profit from offering open-source SaaS solutions, the creators and maintainers struggle to make a living or sustain software maintenance. Major cloud-based database providers have taken advantage of this, developing licenses that keep the source open but impose restrictions on hosting without contributing back to the community. These licenses aim to ensure that companies either share modifications or provide financial support. We expect that balancing commercial interests and open-source principles remains an ongoing challenge.
Overall, vector database market is emerging, as we can see the growth of generative AI and domain-specific applications. We can expect the widespread adoption of vector databases across industries for text generation, image recognition and media content enhancement. On the other hand, open SaaS vector databases may pose a concern to users because of their reliability and security.
Investment Insights
LangChain, a trending framework that provides all-in-one generative AI solutions, enhances contextual awareness and domain-specific reasoning. The core behind LangChain, vector database market are leading many tech firms and startups to make notable strides in this field. This market has attracted substantial funding rounds and valuations, indicating investors' confidence and interest in vector databases.
Prominent startups in vector databases include Chroma, Zilliz, Pinecone, Qdrant and Weaviate have secured significant funding in 2023 and are well-positioned to capture notable market share. They offer customized SaaS in areas such as recommendation systems, image search, and professional knowledge management. Vector databases have the potential to enhance Language Models (LLMs) by enabling similarity search based on inverted indexes and efficient vector computation. While the competition among startups is fierce, traditional database providers like PostgreSQL, Oracle, and MongoDB have leveraged the saturated market to enhance their products by introducing plugins and extensions that cooperate with their existing offerings.
On the other hand, the current application market for LangChain is still in its nascent stage. The growing demand for contextual reasoning and open-source projects like ChatPDF, Serper, Dr. Claude, and GPTeam creates substantial opportunities in various vertical industries. It is anticipated that these application scenarios will attract more traditional industries, such as education, healthcare, and logistics, to shift their focus toward the generative AI landscape and develop their own professional AI assistants.
In terms of the business model, we have witnessed LangChain, vector databases and other vertical applications are open SaaS. The initial goal of open source software is to provide radical transparency and to make technology freely available instead of generating immediate revenue, but this can lead to increase market competition and dilute the unique selling proposition of the original applications. In addition, converting open-source users into paying customers can be challenging. While some users may be willing to pay for additional services or support, finding the right balance between providing value-added services and maintaining the open-source ethos is crucial. Navigating the challenges of the open-source business model requires careful planning, effective community engagement, strong value propositions, and a well-executed monetization strategy. By addressing these challenges, LangChain and other open-source projects can position themselves for long-term success in the rapidly evolving landscape of generative AI.